
 [Model Drift] Model Drift에 대한 A to Z # 1. 정의와 유형
[Model Drift] Model Drift에 대한 A to Z # 1. 정의와 유형
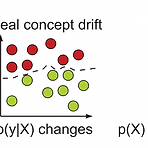
Model Drift Introduction 대부분의 머신러닝 모델들이 가정하는 강력한 전제는 indepedent identical data입니다. 즉, 머신러닝 모델들은 모델이 학습한 패턴들이 변하지 않는 것을 가정합니다. 하지만 실제로는 시간이 지남에 따라 고객/환경/상품 등등이 변하고 데이터의 패턴 역시 끊임없이 변화합니다. 배포된 머신러닝 모델이 끊임없이 새로운 데이터에 대한 예측을 수행하지만, 새로운 데이터는 기존 모델의 학습 데이터와는 다른 확률 분포를 가져 모델의 성능은 하락하게 됩니다. 이렇게 변화하는 환경에 따라 모델의 성능이 저하되는 현상을 Model Drift라고 합니다. 따라서 머신러닝 모델을 배포한 후에도 Model Drift가 언제 발생했는지 발견하고, 필요에 따라 데이터의 패턴..
Data Science&AI
2023. 5. 29. 12:35
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- data drift
- 오토인코더
- 추천시스템
- 최신시계열
- AutoEncoder
- pandas-gpt
- pandas-ai
- Generative BI
- SQLD
- amzaon quicksight
- Concept Drift
- 시계열딥러닝
- Model Drift
- Data Drift와 Concept Drift 차이
- On-premise BI vs Cloud BI
- 모델 배포
- SQLD 정리
- NHITS설명
- Data Drift Detection
- 비즈니스 관점 AI
- 모델 드리프트
- amazon Q
- 생성형BI
- Tableau vs QuickSight
- 영어공부
- 모델 드리프트 대응법
- 영화 인턴
- Model Drift Detection
- SQLD자격증
- 데이터 드리프트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함