
티스토리 뷰
성능이 좋다고 해서 꼭 좋은 추천을 하는 것은 아니지만, 추천 시스템의 정합성을 알 수 있는 대표적인 평가지표에 대해서 알아보고자 합니다.
평점 예측에 사용되는 평가지표
⬛ RMSE(Root Mean Squre Error)
- 평점 등 예측 문제의 추천 성능을 평가할 때 사용하는 지표
- 관측값과 실제값 사이의 오차(잔차)의 제곱을 산술평균한 값의 제곱근
- RMSE가 낮을수록 추천 알고리즘의 성능이 더 좋다고 정량적으로 평가 가능하다.
랭킹 추천에 사용되는 평가지표
⬛ NDCG(Normalized Discounted Cumluative Gain)
- 랭킹 추천에 많이 사용되는 평가 지표로, 정보 검색에서 많이 사용했던 지표
- 검색엔진, 영상, 음악 등 컨텐츠 랭킹 추천에서 주요 평가지표로 활용
- Top-N 랭킹 리스트를 만들고, 더 관심있거나 관련성 높은 아이템 포함 여부를 평가
- 순위에 가중치를 주고 단순한 랭킹이 아닌 데이터의 성향을 반영하기 위한 평가 지표
- MAP(Mean Average Precision), Top K Precision/Recall 등 평가 방법 보완
- 추천 또는 정보 검색에서 특정 아이템에 biased한 경우
- 이미 유명하고 잘 알려진 인기 있는 아이템 또는 한 명의 사용자에 의해서 만들어진 랭킹 등 문제

- 정답 랭킹과 현재 점수를 활용한 랭킹사이의 점수를 cumlative하게 비교 (랭킹 : 상위 아이템 p개, 1에 가까울수록 좋은 랭킹)
- rel(Relvance Score) :
- 사용자가 추천된 각 아이템을 얼마나 관련있는지, 즉 선호하는 지를 나타내는 점수
- binary(관련 여부) 또는 complex value(문제에 따라 세분화된 값)로 표현
- 예를 들어, 아이템이 리스트에 있지만 어떠한 액션도 안한 아이템은 0, 사용자가 클릭했지만 사지 않은 아이템은 1, 사용자가 예전에 샀다면 2

- CGp(Cumulative Gain) :
- 상위 아이템 p개에 대해서 동일한 비중으로 합함
- 추천 아이템의 순위를 고려하지 않음
- 아래의 CG5 = 0+2+1+2+0 = 5

- DCGp(Discounted Cumulative gain) :
- reli : i 번째 추천 아이템의 관련성 점수
p : 추천 시스템에서 추천한 상품 수
i : 추천 아이템의 순위 목록에서 추천 아이템의 위치 - 개별 아이템의 관련성에 log2i로 정규화를 적용. i가 커질수록 weight(log2(i+1))이 증가
- 순위가 낮을수록 가중치를 감소함. (하위권 penalty 부여)
- 추천 길이가 길어질수록 DCG가 증가할 확률이 높아지는 단점이 있음
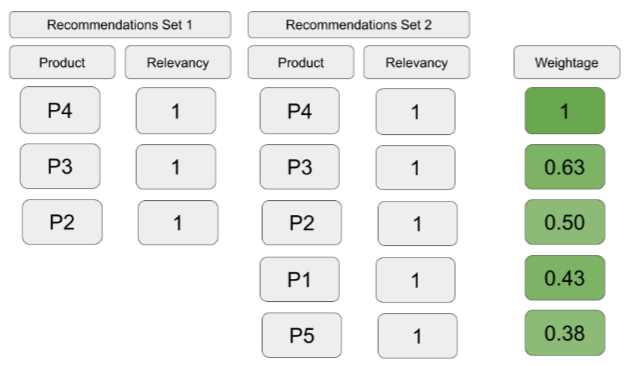
- DCG5 = 0*1 + 2*0.63 + 1*0.5 + 2*0.43 + 0*0.38 = 2.62
IDCG5 = 2*1 + 2*0.63 + 1*0.5 + 0*0.43 + 0*0.38 = 3.76
- reli : i 번째 추천 아이템의 관련성 점수

- NDCGp :
- 이상적인 DCG(IDCG)는 전체 P개의 결과 중 가질 수 있는 가장 큰 DCG값으로, IDCG를 계산하여 최종 NDCG를 계산.
- 0~1 사이의 값으로 1과 가까울수록 우수한 추천시스템.

- .
- 단점1) 관련 없는추천에 대한 패널티가 없음.
관련 없는 추천 아이템을 포함하지 않으므로 Set1이 더 나은 집합이나 NDCG값은 같다.
- 단점1) 관련 없는추천에 대한 패널티가 없음.

- .
- 단점2) 누락된 아이템에 대한 패널티가 없음
관련성이 더 높은 아이템을 Set2에 포함하나 NDCG값은 같다.
- 단점2) 누락된 아이템에 대한 패널티가 없음
⬛ Precision @ K (Top-K)
- Top-K의 결과로 Precision 계산
- 관련 여부를 0 또는 1로 평가
- 예를 들어, Top7 관련 여부가 1-0-1-1-0-0-1일 때, Top-3는 2/3(66.7%), Top-5는 3/5(60%)
⬛ Mean Avearage Precision (MAP)
- 추천 랭킹 또는 겸색 결과에 대한 average precision의 평균값 계산
- 전체 Precision@K (K1, K2, ... KR)에 대한 평균값
⬛ Precision/Recall, AUC
- 분류 문제의 정확도를 검증하고자 할 때 주요 사용되는 평가 지표
- Precision(정밀도) : 예측을 Positive로 한 데이터 중 예측과 실제 값이 Positive로 일치한 데이터 비율 (스팸 메일 진단)
- Recall(재현율) : 실제 Positive한 데이터 중에 예측과 실제 값이 Positive로 일치한 데이터의 비율 (암진단)
- AUC(Area Under Curve) : ROC 곡선의 밑 면적
[참고문헌]
'Data Science&AI' 카테고리의 다른 글
| [AI-언어] 언어를 인식(NLU)하는 방법은? - 토크나이징 / 인코딩 / 토큰 임베딩 (0) | 2023.02.13 |
|---|---|
| [추천시스템] 추천시스템의 한계와 좋은 추천시스템이란? (0) | 2023.02.12 |
| [추천시스템] 추천시스템 A to Z : 추천 알고리즘의 종류 (0) | 2023.02.12 |
| [추천시스템] 추천시스템 A to Z : 추천시스템이란? 사용자와 상품은? 추천 시스템이 풀고자 하는 문제는? (0) | 2023.02.12 |
| Model-Based Learning (0) | 2022.11.29 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- On-premise BI vs Cloud BI
- Model Drift
- 영화 인턴
- SQLD
- Generative BI
- NHITS설명
- SQLD자격증
- SQLD 정리
- Model Drift Detection
- Data Drift Detection
- amazon Q
- 시계열딥러닝
- 최신시계열
- pandas-ai
- 비즈니스 관점 AI
- 모델 드리프트 대응법
- Tableau vs QuickSight
- amzaon quicksight
- Data Drift와 Concept Drift 차이
- pandas-gpt
- 모델 드리프트
- 추천시스템
- 모델 배포
- 영어공부
- 오토인코더
- 데이터 드리프트
- data drift
- 생성형BI
- Concept Drift
- AutoEncoder
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
글 보관함