
티스토리 뷰
📚 논문 : "Attention is all you need"
💻Github : https://github.com/jadore801120/attention-is-all-you-need-pytorch
GitHub - jadore801120/attention-is-all-you-need-pytorch: A PyTorch implementation of the Transformer model in "Attention is All
A PyTorch implementation of the Transformer model in "Attention is All You Need". - GitHub - jadore801120/attention-is-all-you-need-pytorch: A PyTorch implementation of the Transformer mo...
github.com
Transformer 구조를 제안한 "Attention is All you Need"는 2017년에 발표된 가장 흥미로운 논문 중 하나입니다.
각종 기계번역 대회에서 세계 최고의 기록 보유하고 있고
BERT, GPT 등 최신 언어 AI알고리즘은 모두 Transformer 아키텍처 기반으로 삼고 있습니다.
Transformer는 어떻게 탄생하게 되었을까?
- RNN의 long-term dependency를 해결하기 위한 노력으로 LSTM, GRU 도입
- Seq2Seq에서 먼 거리에 있는 토큰 사이의 관계를 모델링(hidden state)하기 위해 Attention과 같은 알고리즘 등장
- Attention을 통해 먼 거리에 있는 문맥 정보도 가지고 와서 사용할 수 있게 되었지만
시퀀스 토큰을 타임스텝별로 하나씩 처리(즉, Sequential한 입력값이 주어져 병렬 처리 불가능)해야 하는 RNN의 특성 상, 느리다는 단점 여전히 해결되지 않음- 시퀀스 토큰을 타입스텝별로 하나씩 처리 = 모든 타임 스텝에서 hidden이 계산된 후에야 attention이 진행 가능
→ Sequential한 입력값이 주어져 병렬 처리 불가능
- 시퀀스 토큰을 타입스텝별로 하나씩 처리 = 모든 타임 스텝에서 hidden이 계산된 후에야 attention이 진행 가능
RNN의 단점인 느리다는 것과 long-term dependency 모델링 어렵다는 점을 동시에 해결할 수 있는 방법으로 고안된 것이 바로 Transformer입니다. Seq2Seq모델에 RNN을 제거하고 "Attention Mechanism"으로 연결하게 된다.
다시 말해,
(1) RNN없이 입력된 시퀀스에 있는 정보를 잘 모델링하고
(2) 주어진 문맥 내의 모든 정보를 고려해 자연어 토큰들의 정보를 모델링할 수 있으며,
(3) 병렬처리가 가능해 속도가 빠른 모델이다.
Transformer의 핵심
- 입력데이터끼리의 Self attention을 사용해 Recurrent Unit 없이도 문장을 모델링하여
문장 내 단어들이 서로 정보를 파악하며, 해당 단어와 주변 단어간의 관계, 문맥을 더 잘 파악할 수 있게 됨 - Self Attention : Attention을 통해 각 토큰이 집중해야 할 문맥 정보를 점수 매기고, 가중합
| 이전 RNN 계열 | Transformer |
| 타임스텝별로 들어오는 인풋을 이전 정보와 결합해 hidden representation 생성 (이전 스텝이 모두 처리되어야 함) |
Self attention을 통해 한 번에 문맥 내에 있는 모든 토큰 정보를 고려해 hidden representation 생성 |
| 각 토큰이 sequential하게 RNN cell에 입력되므로 입력 시퀀스들의 순서(위치) 정보가 보존 |
시퀀스(토큰)을 한번에 다 입력하는 형태이므로 seq2seq와 다르게 순서(위치)정보가 보존되지 않음 |
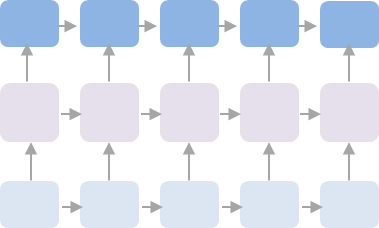 |
 |
Transformer의 아키텍처 - # 0. Summary
- RNN이나 CNN없이 오로지 Attention과 Dense layer(feed forward network)만으로 인풋을 연결한 구조
- Transformer는 기본적으로 번역 태스크를 수행하기 위한 모델이므로 Encoder - Decoder 구조를 지닌 Seq2Seq model
- 각 Encoder와 Decoder는 L개의 동일한 Block이 stack된 형태를 지님
- Encoder Block 구성
- Multi-head self-attention
- Position-wise feed-forward network
- Residual connection
- Layer Normalization
- Encoder 구조 Summary
- Encoder의 Input과 Output 크기 동일
- [Input Embedding] 인풋 시퀀스를 임베딩
[Positional Encoding] 위치 정보를 더해주고
[Multi-head attention] scale dot-product attention을 통해 인풋에 있는 모든 문맥 정보를 사용해 토큰의 representation생성
[Residual Connection] [Layer Normalization]
[Feed Forward] Fully-Connected Network를 이용해 정보를 변환 - 인코더에서는 인풋 문장 안에 있는 토큰들간의 관계를 고려하는 self-attention사용
- 인코딩 단계에서는 [Self-attention + Feed Forward] 레이어를 여러 층 쌓아 인풋 토큰들에 대한 representation 생성
- 인코더 layer #l이 Output = 인코더 layer #l+1의 Input
- 마지막 layer의 Output은 Decoder에서 Attention에 사용
- Decoder 구조 Summary
- 기본적인 Encoder Block 구성과 동일
- Multi-head self-attention과 Position-wise FFN 사이에 Cross-attention(encoder-decoder attention) 모듈 추가
- attention 통해서 현재 output에 대해 모든 인코더의 hidden state를 고려할 수 있음
- 디코딩 시에 미래 시점의 단어 정보를 사용하는 것을 방지하기 위해 Masked self-attention을 사용
- 디코터에서는 디코더 히든과 인코더 히든들간의 attention을 고려해 토큰을 예측함
- 디코딩 단계에서는 [디코더 히든사이의 Self Attention , 인코더 아웃풋과의 attention]
- 디코더 layer #l이 Output = 디코더 layer #l+1의 Input
- 마지막 layer의 Output은 최종 예측에 사용
- head마다 input 문장의 어디에 집중할지가 달라 가공이 가능하여 훨씬 성능이 좋음

다음으로 아키텍처에 대해 더 세부적인 설명을 해보도록 하겠습니다.
Transformer의 아키텍처 - # 1. Encoder의 Input
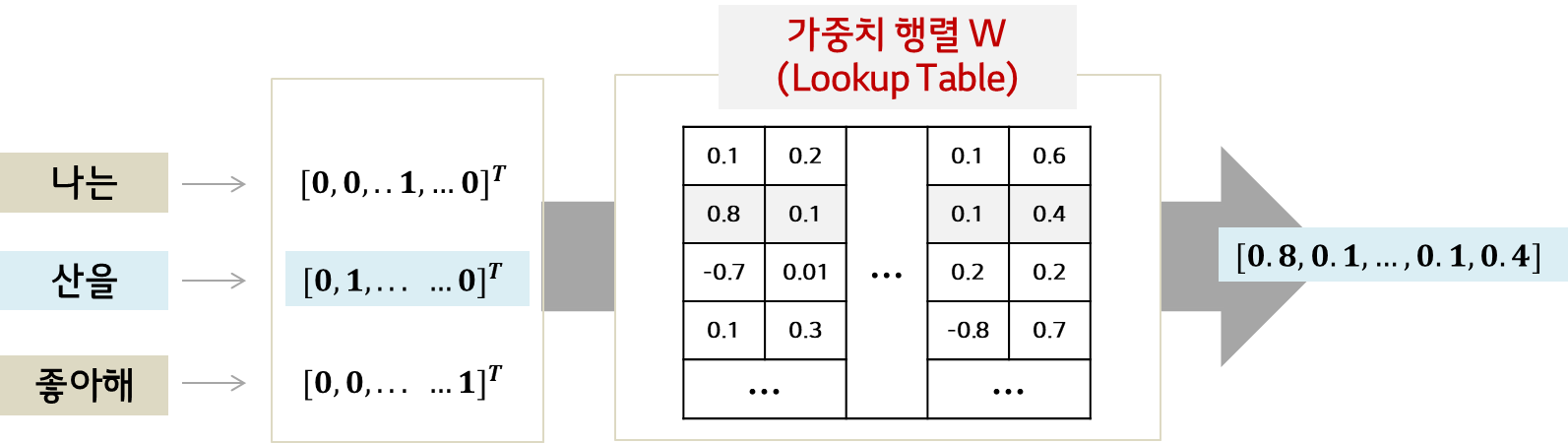
- 문장의 각 시퀀스(토큰)를 학습에 사용되는 벡터로 임베딩하는 embedding layer 구축
- 임베딩 행렬 W에서 look-up을 수행하여 해당하는 벡터를 반환
- W : 훈련 가능한 파라미터
Transformer의 아키텍처 - # 2. Encoder의 Positional Encoding
- Transformer는 input자체를 Sequential하게 입력하는 것이 아니라
하나의 matrix로 한번에 받아 attention을 계산하는 형태이므로,
▶각 토큰이 병렬적으로 또는 독립적으로 연산하는 과정을 거치므로,
Sequence가 내포하고 있는 순서 정보의 특징을 반영하지 못함 - [예시] 만약 [철수] [가] [영희] [를] [좋아해]라는 인풋을 self-attention레이어 넣으면 어떤 결과?
[영희] [가] [철수] [를] [좋아해] 라는 문장을 넣은다면?
같은 토큰임베딩 매트릭스와 가중치 매트릭스(Q, K, V)에 대해 두 문장은 완전히 같은 문장으로 표현됨 - 토큰의 순서정보를 반영해주기 위해 Position Encoding 사용
- Positional Embedding을 Input Embedding에 더해 최종 input으로 사용
(Input ▶ Embeddings + Positional Encoding = Embedding with Time signal ▶ Encoder) - Positional Encoding 차원 = Embedding 차원
- [조건]
- 각 토큰의 위치마다 유일한 값을 지녀야 함
- 토큰 각 차이가 일정한 의미를 지녀야 함 (멀수록 큰 값)
- 더 긴 길이의 문장이 입력되어도 일반화가 가능해야 함
- sin & cos 함수를 사용해 토큰의 절대 위치(0번째, 1번째)에 따른 인코딩을 만들어냄
(sin&cos 함수를 사용해 인코딩 하는 방법은 'sinusoidal positional encoding'이라고 부름)
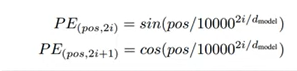
- 위치에 따라 조금씩 다른 파형이 토큰 임베딩에 더해지고, 이를 통해 트랜스포머 블록은
위 [예시]의 두 문장을 다르게 인코딩할 수 있음

- 임의의 인코딩을 만들어내는 방식 대신 Positional Encoding에 해당하는 부분도 학습할 수 있음
- 위치를 나타내는 one-hot-vector를 만들고, 이에 대해 토큰 임베딩과 비슷하게 위치 임베딩을 진행
Transformer의 아키텍처 - # 3. Encoder의 Scaled Dot Product Attention
- Multi-head-self-attention에서 사용하는 Scaled dot-product attention이 핵심
- 문장 내 어떻게 관계를 학습할 수 있을까의 답!
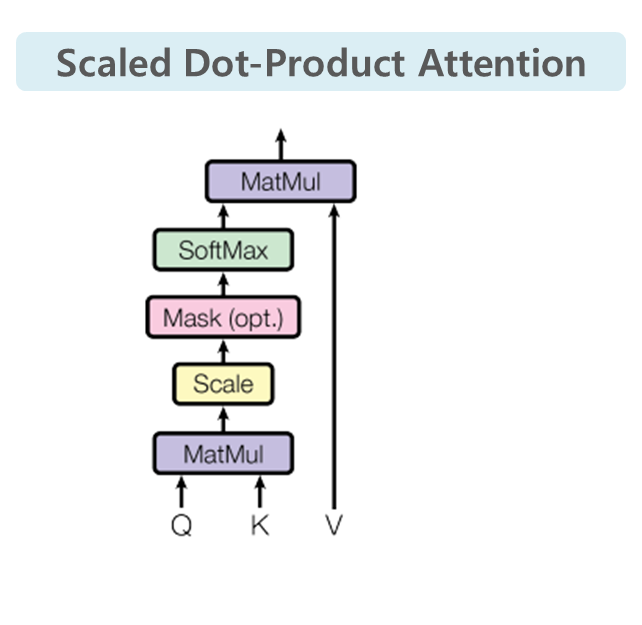
- dot-product로 attention 점수를 계산하고 그 점수를 scaling
- Step1) Attention 대상이 되는 토큰들을 Key와 Value, attention하는 토큰을 Query로 변환(행렬곱)
- 인풋 문장의 토큰 임베딩을 통해 각각의 토큰은 h차원으로 변환한 후,
매트릭스 곱을 통해 각각의 토큰에 대해 3가지 벡터 생성 ▶Query-Key-Value로 동작
(L : 시퀀스 길이, d : attention depth)
- 인풋 문장의 토큰 임베딩을 통해 각각의 토큰은 h차원으로 변환한 후,
| Query | Key | Value | |
| 관심 있는 문맥 정보를 가지고 오고자 하는 토큰 벡터 (Self attention의 주체) |
Query와 문장의 각 토큰 사이의 attention score을 계산(모델링)하기 위한 벡터 (Query와의 비교 대상) |
Key값들을 Query와 Key간의 유사도에 따라 가중합하여 Query에 반영할 때 가중합의 대상으로 사용할 값 |
|
| 현재의 hidden state값 | hidden state와 영향을 주고 받는 값 |
각 토큰에 대한 새로운 representation으로, 정보를 담고 있는 벡터. Key가 갖고 있는 실제 값 |
|
| 검색어 | 다른 주변의 토큰들 (Key1, Key2, ...) |
Attention Output은 Value에 Attention Score을 곱하여 계산됨 |

| [표현식 의미] □ (Dk) : Query가 Projectiong하는 차원 (M) : Key의 Sequence Length (N) : Query의 Sequence Length □ 내적을 위해 Query와 Key의 차원이 같아야 함 □ M은 각 Key에 해당하는 Value값을 가중합하여 사용 □ Projection된 차원은 달라도 되지만 Row-wise Softmax값에 Value가 내적되어야 하므로, Key의 M에 해당하는 부분과 같아야 함 [분자/분모 의미] □ [분자] dot-product : Query와 Key의 내적으로 이루어짐 □ [분모] Softmax함수의 gradient vanishing 문제 완화 위해 Scaling [Dk] □ 초반에 학습이 잘 되도록 하기 위해 Dk로 scaling □ multi-head 적용하지 않을 때 Dk = 512 □ Dk가 작은 경우, dop-product attention과 additive attention은 유사한 성능 □ Dk가 큰 경우, 내적값이 굉장히 커짐에 따라 특정 softmax 값(가중치)이 1에 근사되어, 이는 gradient가 소실되는 결과를 낳음 □ 하나의 softmax값이 1에 가까워지면 gradient가 모두 0에 수렴하게 되어 학습 속도가 굉장히 느려지거나 학습이 안 될 수 있음 [SoftMax] □ 각 행별 SoftMax를 태워, 각 토큰이 다른 토큰들과 갖는 관계적인 의미를 표현(가중치) |

- Step2) Query에 대해 각 key들과의 내적을 통해 attention 가중치 계산.
이 때 scale된 벡터 내적에 Softmax를 취하는 방식으로 '확률 분포'와 같이 만듦- Query벡터(검색어)와 각각의 key벡터들을 내적(dot product)하여 어텐션 점수(비중, 유사도)를 계산
(예시) [I] 토큰 입장에서 [I] [am] [a] [men]의 중요도를 계산
- [I]와의 점수 : 128, [am]과의 점수 : 32, [a]와의 점수 : 32, [men]과의 점수는 128
- dot-product 연산을 했기 때문에 query와 key벡터의 차원에 따라 숫자는 아주 커짐
▶ 쿼리 벡터의 차원의 squared-root를 취해 이 점수를 scaling. 그 결과 16, 4, 4, 1
- 이 점수에 softmax를 취해 확률값과 비슷한 Attention distribution을 만듦
- Step3) 가중치를 이용해 Value를 가중합하여 Query의 representation을 업데이트
(Attention 분포에 따라 Value를 가중합하여 Attention Value(output)을 구함)- 위에서 구한 Attention distribution을 가중치로 사용하여 value 벡터를 가중합함
- 토큰이 어떤 정보와 관련있을지 (WQ, WK), 어떤 정보를 가지고 와야 할지(WV)
- Query벡터가 Key와의 유사도 정보를 반영한 벡터로 변형
(예시) 이렇게 계산된 벡터는 query토큰인[I]에 대한 representation
- [I] [am] [a] [men]에 대한 가중치가 각각 0.4, 0.1, 0.1, 0.4로 계산되어
완성된 벡터는 [I]와 [men]의 정보가 많이 반영된 벡터
- 각 Key의 가중치 * Value의 합
▶ self attention을 통해 [I] 토큰이 전체 인풋 텍스트의 정보를 반영하여 [men]의 의미까지 가진 representation이 됨
(예시) query = 'Key1' | attention = {'key1' : 'value1', 'key2' : 'value2', 'key3' : 'value3'} attention[query] = 'value2'
- Attention의 Output은 Encoder의 Input과 동일한 크기의 텐서
- padding에 대한 attention score는 0(Q*Kt계산 시 -1e9로 입력)으로, loss계산에서도 참여 안 함
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
output = torch.matmul(attn, v)
return output,
Self-attention의 의미
- 인풋 시퀀스 전체에 대해 attention을 계산해 각 토큰의 representation을 만들어 가는 과정으로,
업데이트된 representation은 문맥 정보를 가지고 있음 - 예를 들어, "차은우는 #년에 태어났다. 그는 최근에 #에 출연했다"라는 인풋에 대해 self-attention을 적용하면
'그'에 해당하는 representation은 '차은우'에 대한 정보를 담게 된다. - scale dot-product attention은 matrix로 계산할 수 있어 RNN처럼 이전 토큰이 처리되길 기다릴 필요가 없음
- 이러한 과정은 타임스텝에 따른 지연 없이 한번에 연산하므로,
인풋으로 들어온 모든 문맥의 정보를 foregetting 없이 반영 가능 - 인풋 텍스트의 각 토큰에 weight를 곱해 Q, K, V 를 만들고 이 벡터를 사용해 토큰의 문맥 정보를 업데이트하는 과정
Transformer의 아키텍처 - # 4. Encoder의 Multi-head Attention
- 각 토큰에 대해 인풋 컨텍스트로부터 관련된 문맥 정보를 포함해 의미를 모델링하기 위해 사용
- 전체 입력 문장을 전부 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야 할 단어와 연관있는 단어 부분을 좀 더 집중
- Attention head별로 각기 다른 측면에서 토큰간의 관계와 정보를 학습할 수 있음. 약간의 앙상블 개념?
- Attention 계산 과정을 여러 weight를 사용해 반복하고 그 결과를 concat하여 최종 attention output 계산
(이는 CNN filter을 여러 장 사용함으로써 이미지에 있는 다양한 특성을 포착하는 것처럼,토큰 사이의 다양한 관계를 포착하기 위함임) - Scaled dot-product attention(WQ, WK, WV 매트릭스)을 한 번에 계산하는 것이 아니라
여러 개의 head에서 Self-Attention이 수행되어 계산함
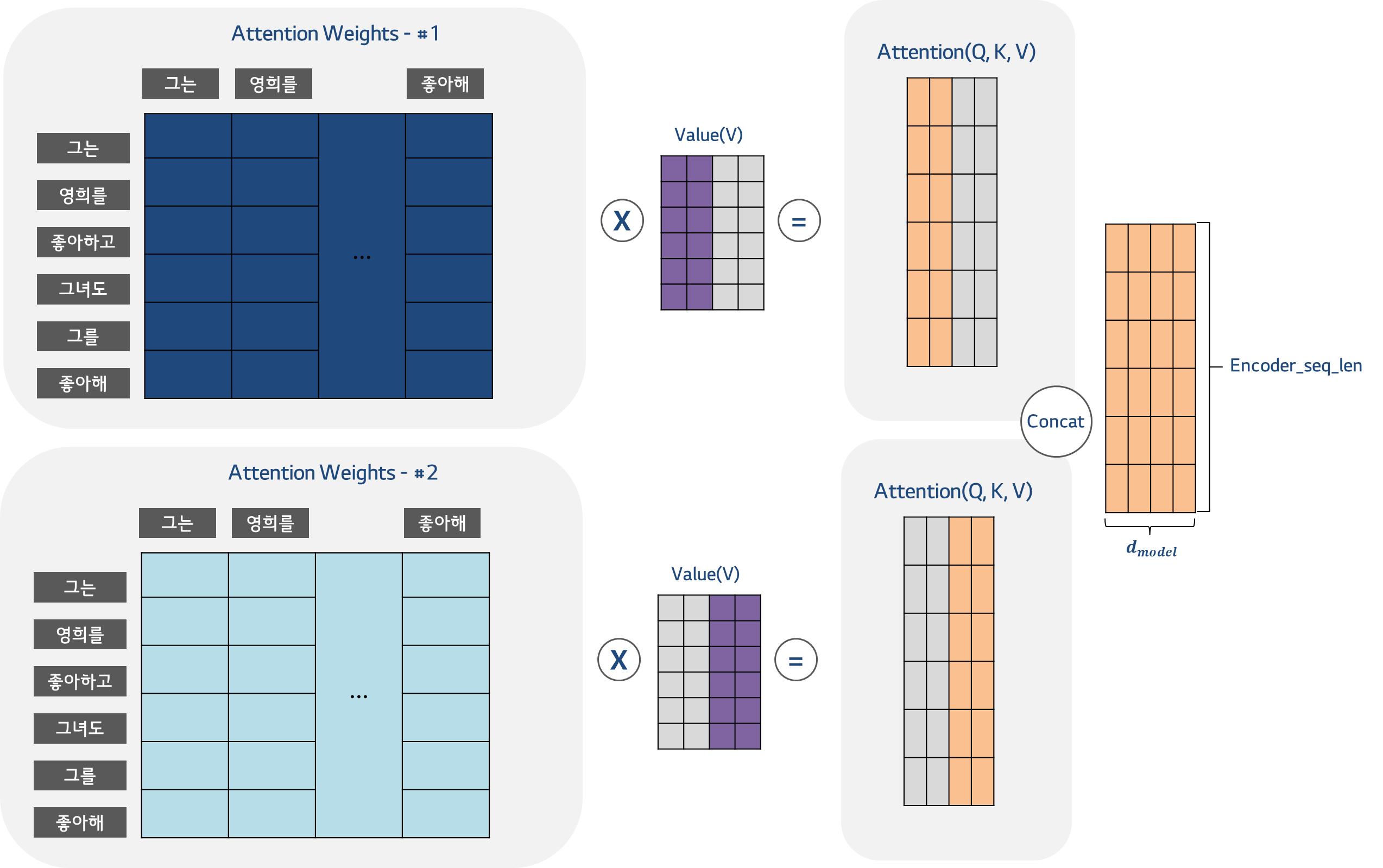

[과정]
- N x Dm 크기의 임베딩에 대한 Q, K, V로 head의 수(하이퍼파라미터)만큼 attention을 계산
- 각 head의 Output은 Concatenate됨
- concatenate된 각 head들의 output은 원래 Dmodel의 차원으로 다시 Projection되어 다음 layer에 전달
- Step1) Sequence Embedding (Sequence Length x Embedding dimension(Dmodel)) ▶
Step2) Weight matrices for Q, K, V (head수 만큼) ▶
Step3) head 수만큼 attention 계산 ▶
Step4) 각 attention head의 output concatenate ▶
Step5) Dmodel 차원으로 다시 Projection
(Step2)
- Sequence Embedding에서 Input sequence embedding 전체를 Q, K, V를 구하는 Weight matrices를 통해
특정 차원을 가지는 Q, K, V를 matrices를 만듦
(embedding dimension을 head의 수 만큼 쪼개어 attention을 구하는 것이 아니라) - Sequence Embedding을 Projection시킨 W를 head별로 나뉘어 sequence Embedding과 내적함
- Concat된 형태의 Weight를 만들어두고 각각의 head 에 따라 해당 Weight를 나누어 사용
- Q, K, V를 projection하는 weight matrices는 처음부터 독립적으로 head수만큼 정의하지 않고,
n_Head*d_k의 dimension을 갖는 weight matrix를 만든 후 나눠서 사용하는 방식
(Step5)
|
(코드)
- Transformer 클래스 d_model , n_head, d_k = d_model/n_head , d_v = d_model/n_head
- 앞서 생성한 Weight Matrix의 차원을 조정하여 head수만큼 Q, K, V Weight의 영역 구분
- 즉, sequence_length x (n_head x d_k(v))의 크기를 갖는 weight matrix를 기반으로
n_head수만큼 attention이 계산될 수 있도록 차원을 변경하여 사용 = 병렬적으로 사용 - Attention 계산 후 head의 output 차원을 다시 조정하여 concatenate된 matrix 생성
- concat 후 W0 matrix를 통해 d_model의 차원으로 다시 projection됨
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv)
# Separate different heads: b x lq x n x dv
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
q += residual
q = self.layer_norm(q)
return q, attn
Transformer의 아키텍처 - # 5. Encoder의 (Position-Wise) Feed Forward Network

- Feed Forward는 Dense Layer, Multi-head attention에서 나온 hidden state 정보를 가공하는 레이어
- Attention을 거친 후 Feed Forward Network(nn.Linear)에 태움
- Fully connected feed-forward module를 적용하는 부분
- Position마다 즉 개별 단어마다 적용되어 position-wise
- 같은 encoder layer 내(한 블록 내 단어 간의) FFN의 parameter(w, b)는 공유됨
- 각 토큰이 hidden layer로 한번 projection 되고 다시 output 차원(Input과 동일 차원)으로 네트워크 거침
- 서로 다른 head로부터 나온 독립적인 multi-head attention 결과(heads)를 process하는 것을 의미
- FFN의 Input : 이전 layer의 Output,
- ReLU : max(0, 값)
- 보통 d_hid(D_f) > d_model(D_m)
class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x
Transformer의 아키텍처 - # 6. Encoder의 Residual Connection and Normalization
- Gradient exploding / vanishing 문제를 완화하고, deep한 네트워크를 안정적으로 학습하기 위해 도입
- Add & Norm은 residual connection을 만들고, 레이어 정규화를 통해 모델이 정보를 잃어버리지 않도록 하기 위해 있는 레이어
- Residual connection : 다음과 같이 layer을 거친 이후에 layer 거치기 이전의 x값을 더해주는 것을 의미
- 이전 레이어의 아웃풋을 다음 레이어에 다이렉트로 이어주어서 layer를 깊게 쌓아도 gradient vanishing이 일어나지 않게 하는 기법
- ADD = Residual Connection, Input을 W(Q, K, V)로 Query, Key, Value를 얻고 Multi Head Attention으로 얻은 행렬을 input값을 더해주는 것

- Layer Normalization : 각 중간층의 출력을 정규화한 것, 정규화한 후 다음 Feed Forward로 넘겨줌
(x : eng_seq_len * d_model 차원)
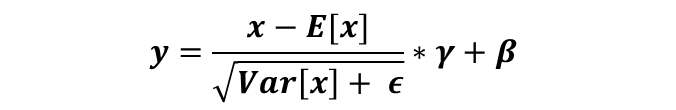
- torch.nn.LayerNorm(normalized_shape = d_model, eps, ) : 마지막 차원에 대해 normalize

Transformer의 아키텍처 - # 7. Decoder
- 앞서 인코더의 최종 Output(Key, Value)이 Decoder의 Multi-head Attention에 이용됨
- 기본적인 Encoder와 비슷한 구조
- 문장의 각 시퀀스(토큰)을 one-hot encoding 후 학습에 사용되는 벡터로 임베딩하는 embedding layer 구축
- 임베딩 행렬 W에서 look-up을 수행하여 해당하는 벡터를 반환(W : Trainable parameter)
- Positional Encoding 도 똑같이
class Decoder(nn.Module):
''' A decoder model with self attention mechanism. '''
def __init__(
self, n_trg_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, n_position=200, dropout=0.1, scale_emb=False):
super().__init__()
self.trg_word_emb = nn.Embedding(n_trg_vocab, d_word_vec, padding_idx=pad_idx)
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
DecoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):
dec_slf_attn_list, dec_enc_attn_list = [], []
# -- Forward
dec_output = self.trg_word_emb(trg_seq)
if self.scale_emb:
dec_output *= self.d_model ** 0.5
dec_output = self.dropout(self.position_enc(dec_output))
dec_output = self.layer_norm(dec_output)
for dec_layer in self.layer_stack:
dec_output, dec_slf_attn, dec_enc_attn = dec_layer(
dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask)
dec_slf_attn_list += [dec_slf_attn] if return_attns else []
dec_enc_attn_list += [dec_enc_attn] if return_attns else []
if return_attns:
return dec_output, dec_slf_attn_list, dec_enc_attn_list
return dec_output,- Multi-head self-attention과 Position-wise FFN 사이에 Cross-attention(encoder-decoder attention) 모듈 추가
- attention 통해서 현재 output에 대해 모든 인코더의 hidden state를 고려할 수 있음
- 디코터에서는 디코더 히든과 인코더 히든들간의 attention을 고려해 토큰을 예측함
- 디코딩 단계에서는 [디코더 히든사이의 Self Attention , 인코더 아웃풋과의 attention]
- [Input] dec_output : Query | enc_output : Key | enc_output : Value ▶
[Output] dec_output | attention(디코더-인코더 히든 간)

- 디코딩 시에 미래 시점의 단어 정보를 사용하는 것을 방지하기 위해 Masked self-attention을 사용
(Self Attention Encder에서는 소스마스크, Decoder에서는 타겟마스크 사용)
(Attention 가중치를 구할 때 대상 토큰의 이후 시점의 토큰은 참조하지 못하도록 마스킹) - diagonal 윗부분 마스킹
- Padding token의 위치에 대한 마스킹

- Encoder와 마찬가지로 head 수 만큼 attention을 구하고 concatenate(dec_seq_len x D_model)을 한 후,
ADD + Layer Normalization을 수행 - Decoder의 input과 동일한 크기의 tensor의 Output

- 최종 layer의 output은 최종 예측에 사용되어, Linear + Softmax에 태움
#####
self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False)
#####
def forward(self, src_seq, trg_seq):
src_mask = get_pad_mask(src_seq, self.src_pad_idx)
trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq)
enc_output, *_ = self.encoder(src_seq, src_mask)
dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask)
seq_logit = self.trg_word_prj(dec_output)
if self.scale_prj:
seq_logit *= self.d_model ** -0.5
return seq_logit.view(-1, seq_logit.size(2))
Transformer의 실험 결과
- (A) head가 적당히 많은 경우 성능 향상을 기대할 수 있으며, 지나치게 많아지면 오히려 성능이 하락
- (B) Key의 크기를 줄이면 모델의 성능이 하락할 수 있음
- (C) 모델의 사이즈가 클수록 성능이 향상되는 경향이 있음
- (D) Regularization의 일종인 Drop-Out과 Label Smoothing이 성능 개선이 효과적임
(Label Smoothing :레이블에 오류가 존재할 수 있고 overconfidence를 어느 정도 방지)

Transformer Summary
- 인풋 문장에 있는 모든 토큰의 정보를 타임스텝 진행에 따른 forgetting없이 끌어오면서
Positional Encoding을 통해 위치 간의 정보까지 모델링할 수 있는 Transformer - [장점] RNN을 통해 각 스텝의 hidden state이 계산되기를 기다리지 않아도 된다!
즉, 문장에 있는 모든 단어의 representation들을 병렬적으로 한번에 만들 수 있고,
학습 시간 단축에 기여 - GRU, LSTM 같은 아키텍처 없이도 Long-term dependency를 해결한 새로운 방식
- 순차적 계산이 필요 없기 때문에 RNN보다 빠르면서도 맥락 파악을 잘하고,
CNN처럼 일부씩만을 보는 것이 아니고 전 영역을 아우른다. - [단점] 이해력이 좋은 대신에 모델의 크기가 엄청 커지며 고사양의 하드웨어 스펙을 요구
▶이러한 한계를 보완하기 위한 다양한 경량한 방안이 연구되고 있음
'Data Science&AI' 카테고리의 다른 글
| [Model Drift] Model Drift에 대한 A to Z # 1. 정의와 유형 (0) | 2023.05.29 |
|---|---|
| [시계열 알고리즘] NHiTS : Neural Hierarchical Interpolation for Time Series Forecasting (0) | 2023.04.04 |
| [딥러닝] Attention에 대한 설명 (0) | 2023.02.18 |
| [딥러닝] Seq2Seq에 대한 설명 (0) | 2023.02.18 |
| [딥러닝] GRU(Gated Recurrent Unit)에 대한 이해 (0) | 2023.02.13 |
- Total
- Today
- Yesterday
- 최신시계열
- pandas-gpt
- SQLD자격증
- 생성형BI
- Model Drift Detection
- Data Drift와 Concept Drift 차이
- Generative BI
- amazon Q
- AutoEncoder
- 모델 배포
- NHITS설명
- 오토인코더
- SQLD 정리
- data drift
- 추천시스템
- 영어공부
- 모델 드리프트 대응법
- 비즈니스 관점 AI
- pandas-ai
- 시계열딥러닝
- 영화 인턴
- Model Drift
- 데이터 드리프트
- Data Drift Detection
- Concept Drift
- 모델 드리프트
- Tableau vs QuickSight
- SQLD
- On-premise BI vs Cloud BI
- amzaon quicksight
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |