
 [Model Drift] Model Drift에 대한 A to Z # 1. 정의와 유형
[Model Drift] Model Drift에 대한 A to Z # 1. 정의와 유형
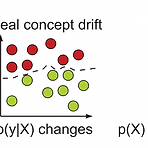
Model Drift Introduction 대부분의 머신러닝 모델들이 가정하는 강력한 전제는 indepedent identical data입니다. 즉, 머신러닝 모델들은 모델이 학습한 패턴들이 변하지 않는 것을 가정합니다. 하지만 실제로는 시간이 지남에 따라 고객/환경/상품 등등이 변하고 데이터의 패턴 역시 끊임없이 변화합니다. 배포된 머신러닝 모델이 끊임없이 새로운 데이터에 대한 예측을 수행하지만, 새로운 데이터는 기존 모델의 학습 데이터와는 다른 확률 분포를 가져 모델의 성능은 하락하게 됩니다. 이렇게 변화하는 환경에 따라 모델의 성능이 저하되는 현상을 Model Drift라고 합니다. 따라서 머신러닝 모델을 배포한 후에도 Model Drift가 언제 발생했는지 발견하고, 필요에 따라 데이터의 패턴..
 [시계열 알고리즘] NHiTS : Neural Hierarchical Interpolation for Time Series Forecasting
[시계열 알고리즘] NHiTS : Neural Hierarchical Interpolation for Time Series Forecasting
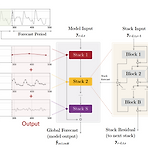
다음은 NHiTS 논문을 정리한 글입니다. Summary N-HiTS는 N-BEATS 모델의 확장으로 N-BEATS에 비해 예측 정확도를 높이고 계산 비용(연산, 메모리 측면)을 줄임 Fully Connected layer로 구성하여 Multi-step을 한번에 예측 N-HiTS는 각 스택이 다른 Scale로 시계열을 포착할 수 있도록 Input에 대해 Maxpool을 적용 (Multi-rate data sampling) 다른 비율로 시계열을 샘플링한 스택은 장기 효과에 특화, 다른 스택은 단기 효과에 특화할 수 있음 계층적 보간(Hierarchical Interpolation)을 통해 얻어진 각 스택의 예측값을 결합하여 최종 예측을 산출, 이렇게 하면 모델이 가벼워지고 장기 시계열을 예측하는 데 더 정..
 [SQLD자격증] # 6. (1과목) 데이터 모델링의 이해 - 데이터 모델과 성능
[SQLD자격증] # 6. (1과목) 데이터 모델링의 이해 - 데이터 모델과 성능
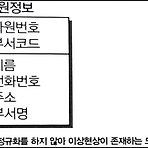
성능 데이터 모델링- DB 성능향상을 목적으로 설계단계의 데이터 모델링 때부터 정규화, 반정규화, 테이블통합, 테이블분할, 조인구조, PK, FK 등 여러 가지 성능과 관련된 사항이 데이터 모델링에 반영될 수 있도록 하는 것 - 분석/설계 단계에서 데이터 모델에 성능을 고려한 데이터 모델링을 수행할 경우 성능저하에 따른 재업무 비용을 최소화 할 수 있는 기회를 가지게 됨 - 데이터의 증가가 빠를수록 성능저하에 따른 성능개선비용은 기하급수적으로 증가하게 됨 - 성능 향상을 위해 튜닝을 수행하면 데이터베이스 모델이 변경될 수 있음 - 성능 데이터 모델링 고려사항 순서 ⓐ 데이터 모델링을 할 때 정규화를 정확하게 수행 ⓑ DB 용량산정을 수행(전체 용량, 월간, 연간 증감율) - 배치를 통해 입력되는 데이터 ..
 [SQLD자격증] # 5. (1과목) 데이터 모델링의 이해 - 데이터 모델의 이해
[SQLD자격증] # 5. (1과목) 데이터 모델링의 이해 - 데이터 모델의 이해
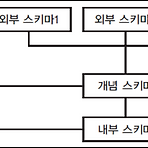
데이터 모델링의 이해⬛ 데이터 모델링 - 데이터 모델링은 현실 세계를 데이터베이스로 표현하기 위해서 추상화 한다. - 데이터 모델링을 하기 위해서는 고객과의 의사소통을 통해 고객의 업무프로세스를 이해해야 한다. - 고객의 업무 프로세스를 이해한 후 데이터 모델링 표기법을 사용해서 모델링을 한다. - 데이터 모델링은 고객이 쉽게 이해할 수 있도록 복잡하지 않게 모델링 해야 한다. - 데이터 모델링은 고객의 업무 프로세스를 추상화하고, 소프트웨어를 분석, 설계하면서 점점 더 상세해진다. - 데이터 모델링은 고객의 비즈니스 프로세스를 이해하고 비즈니스 프로세스의 규칙을 정의 정의된 비즈니스 규칙을 데이터 모델로 표현 - 데이터 모델링 자체로서 업무의 흐름을 설명(별도의 표기 필요없음)하고 분석하는 부분에 의미..
보호되어 있는 글입니다.
옵티마이저와 실행계획 옵티마이저 - 사용자가 질의한 SQL문에 대해 최적의 실행 방법을 결정하는 역할 수행 - 질의에 대해 실행 계획 생성 - SQL의 실행계획을 수립하고 SQL을 실행하는 데이터 베이스 관리 시스템의 소프트웨어 규칙기반 옵티마이저 - 우선 순위를 가지고 실행계획을 생성 - 우선 순위가 높은 규칙이 적은 일량으로 해당 작업을 수행 - 인덱스 유무와 SQL문에서 참조하는 객체 등을 참고 - 제일 낮은 우선순위는 전체 테이블 스캔 - 제일 높은 우선순위는 ROWID를 활용하여 테이블 엑세스 - 적절한 인덱스가 존재하면 항상 인덱스를 사용하려고 함 비용기반 옵티마이저 - 현재 대부분의 DB에서 사용 - 테이블 및 인덱스 등의 통계정보를 활용하여 SQL문을 처리하는데 필요한 비용이 가장 적은 실..
해당 글은 https://cafe.naver.com/sqlpd/7810 을 참조하고 기출을 풀며, 내용 추가하였습니다.표준 조인INNER JOIN - JOIN 조건에서 동일한 값이 있는 행만 반환, USING이나 ON 절을 필수적으로 사용 - (ANSI 표준) SELECT * FROM A, B WHERE A.aa = B.bb AND B.cc = 'dd' SELECT * FROM A INNER JOIN B ON A.aa = B.bb WHERE B.cc = 'dd' 같은 결과NATURAL JOIN - 두 테이블 간의 동일한 이름을 갖는 모든 칼럼들에 대해 EQUI JOIN 수행 - NATURAL JOIN이 명시되면 추가로 USING, ON, WHERE 절에서 JOIN 조건을 정의할 수 X - SQL Seve..
해당 글은 https://cafe.naver.com/sqlpd/7810 을 참조하고 기출을 풀며, 내용 추가하였습니다.SQL 문장들의 종류DDL (데이터 정의어)CREATE,ALTER,RENAME, DROP, TRUNCATE DML (데이터 조작어)SELECT, INSERT, DELETE, UPDATE (COMMIT 입력해야 함)DCL (데이터 제어어)GRANT(권한 부여), REVOKE(권한 취소)TCL (트랜잭션 제어어)COMMIT(DB에 반영), ROLLBACK(트랜잭션 이전의 상태로 되돌림), SAVEPOINT(저장 지점) [Oracle] SAVEPOINT SVPT; ROLLBACK TO SVPT; [SQL Server] SAVE TRAN SVPT; ROLLBACK TRAN SVPT; DDL - ..
- Total
- Today
- Yesterday
- SQLD
- 최신시계열
- Data Drift와 Concept Drift 차이
- amazon Q
- Concept Drift
- 추천시스템
- Model Drift
- 모델 드리프트 대응법
- SQLD 정리
- 시계열딥러닝
- 영어공부
- AutoEncoder
- 비즈니스 관점 AI
- Tableau vs QuickSight
- 데이터 드리프트
- Data Drift Detection
- Generative BI
- pandas-ai
- 영화 인턴
- 모델 배포
- NHITS설명
- data drift
- On-premise BI vs Cloud BI
- 오토인코더
- Model Drift Detection
- SQLD자격증
- 생성형BI
- pandas-gpt
- 모델 드리프트
- amzaon quicksight
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |