
티스토리 뷰
[생성형AI] Generative BI - Amazon Q & pandas-gpt & pandas-ai
calmmimi 2024. 3. 5. 19:00[ 목차 ]
1. Why Generative BI?
생성형 AI는 챗봇 서비스와 문서 요약, 문서 작성 등 다양한 분야에서 널리 활용되고 있습니다.
이러한 기술은 사용자의 질의에 따라 Tabular Data에서 그래프나 테이블을 생성하는 작업에도 적용될 수 있는데요,
기본적으로 데이터에 기반한 시각화를 위해서는 OLAP툴과 연계하기는 하지만,
사용자가 어느 정도 OLAP툴에 익숙해야만 제대로 활용할 수 있습니다.
그러므로 비전문가들이 데이터에 기반한 자동화된 분석과 시각화를 자유롭게 하기 위해서는
생성형 BI 툴이 필요합니다.
2. Generative BI Tool
ChatGPT를 사용해본 적이 있다면, 그래프나 테이블 형태로 정확한 Output을 내는 것이 어렵다는 것을 잘 알 것입니다.
그런데, 이 ChatGPT와 데이터 manipulation과 분석에 특화된 pandas를 조합한다면 어떨까요?
이것을 실현한 Python Package가 pandas-gpt와 pandas-ai입니다.
이 외에도 CSP들 중 Generative BI에 발빠르게 대응한 기업은 AWS입니다.
AWS 내 BI Tool인 QuickSight에 생성형 AI 어시스턴트인 Amazon Q를 탑재하여 지난해 평가판이 출시되었습니다.
3. Amazon Q in QuickSight
Amazon Q는 업무용으로 설계된 생성형 AI 어시스턴트로,
대화를 통해 정확한 답변을 얻거나, 문제를 해결하고, 콘텐츠를 생성하고 문서를 요약할 수 있습니다.
그리고 애플의 siri와 같이 AWS 내 여러 어플리케이션에 임베디드 되어 Amazon Q를 활용할 수 있습니다.
AWS 내 BI툴인 QuickSight에서 Amazon Q를 사용하게 되면, 다음과 같은 세 가지 기능을 적용할 수 있습니다.
- 스토리 기능: 자연어 프롬프트를 사용하여 몇 분 만에 스토리를 자동 생성하고, 포인트 앤 클릭 옵션을 사용하여 사용자를 지정하며, 다른 사람들과 안전하게 공유할 수 있습니다. Amazon Q는 엄선된 시각 자료에서 데이터 인사이트와 통계를 추출한 다음 대규모 언어 모델(LLM)을 사용하여 스토리를 구성하여 아이디어를 제안합니다. (e.g. “전반적인 영업 실적 동향에 대한 스토리를 작성해 주세요.", " 판매 개선을 위한 몇 가지 전략을 제안해 주세요. ")
- 핵심 요약 기능: 사용자가 대시보드의 주요 내용을 빠르게 이해할 수 있도록 돕는 기능으로, 수십 개의 그래프나 테이블들에 대해 맥락을 파악하거나 변경 사항을 이해하는데 주요한 인사이트를 쉽게 생성하여 제공해줍니다.
- 데이터 Q&A 기능: 사용자가 대시보드 및 보고서에서 제공되는 내용 이상으로 질문에 대한 답변을 얻을 수 있도록 지원합니다. 자연어로 질문을 하면 AI가 제안하는 질문과 관련 데이터 프로필, 자동으로 생성된 시각적 답변을 통해 쉽게 데이터 관련 질문에 답변할 수 있습니다. (모호한 질문에도 적절한 대답을 제공)
QuickSight 내에서 빠르게 테스트해보았을 때, Amazon Q를 활용하여 프롬프트를 입력하면 QuickSight 대시보드에 차트가 그려지는 형태의 결과물을 얻을 수 있었습니다. (※ 다만, 현재까지는 영어 프롬프트만 지원되고 있습니다.)
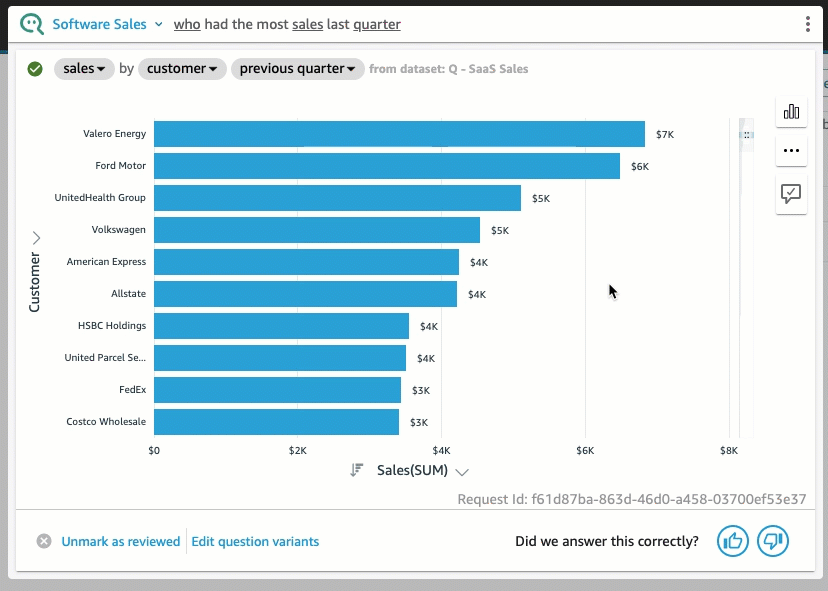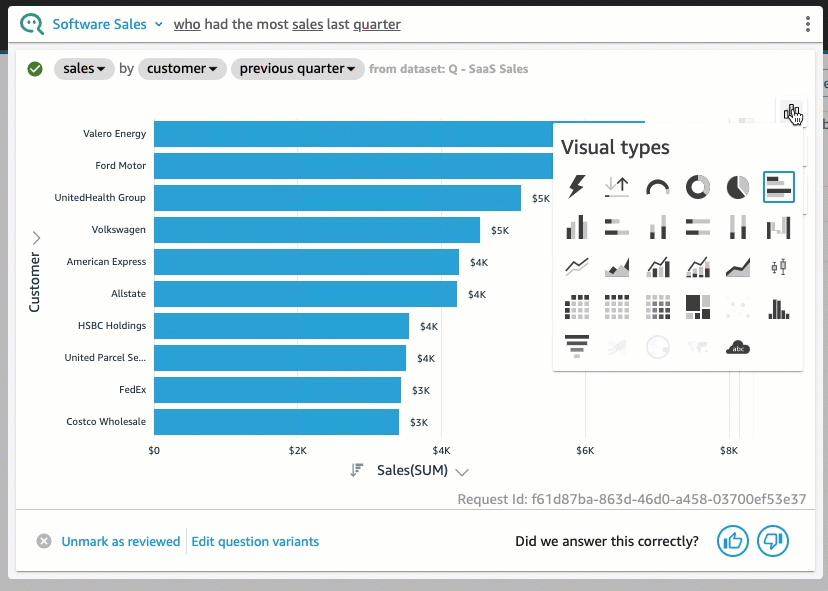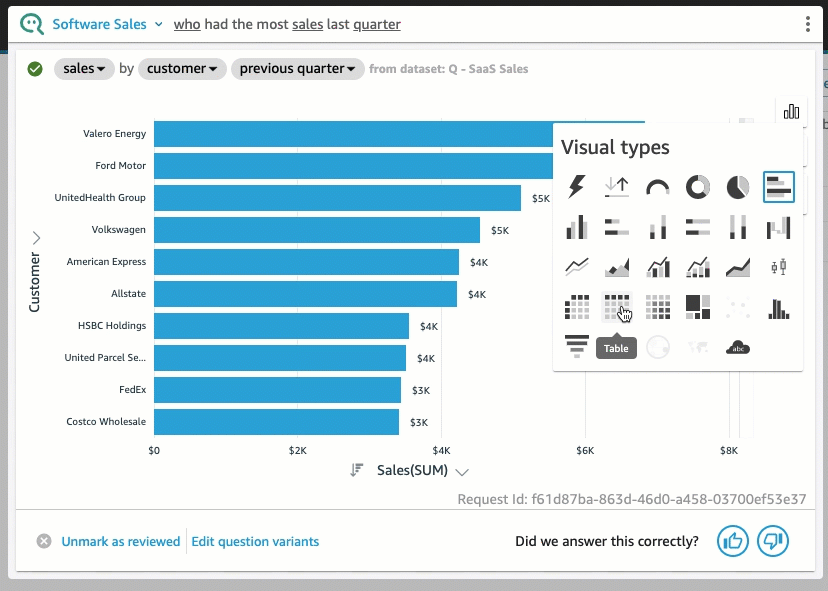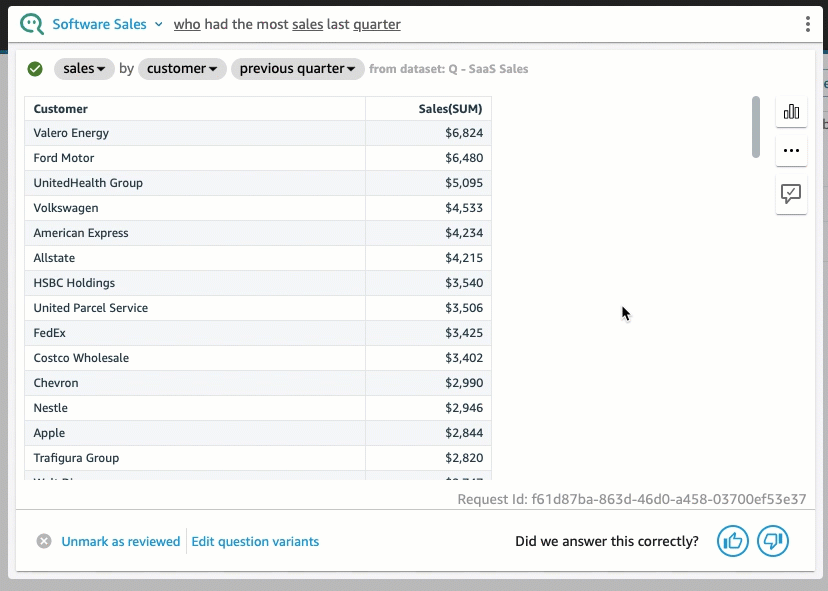
4. Generative BI 파이썬 패키지 - pandas_gpt
pandas_gpt는 자연어 쿼리를 사용하여 pandas dataframe으로 (거의) 모든 작업을 수행할 수 있게 하는 패키지입니다.
프롬프트 엔지니어링을 사용하여 데이터셋의 컬럼명을 기반으로 입력 쿼리에서 함수를 생성하는 방식으로 작동합니다.
다음은 간단한 예제로 실습한 내용입니다.
1) 파이썬 패키지 설치
%pip install -q pandas-gpt
import pandas_gpt
from IPython.display import clear_output, display
clear_output()
2) Open AI-api key 설정
import openai
api_key = '<your api key>'
openai.api_key = api_key
3) 데이터 로드
import pandas as pd
df = pd.read_csv('https://gist.githubusercontent.com/pleabargain/e79e39f56d04278d4e7bc64825de5196/raw/7e64971a126093298cd63644aeaec9d3d78d09b2/sample-sales-data.csv')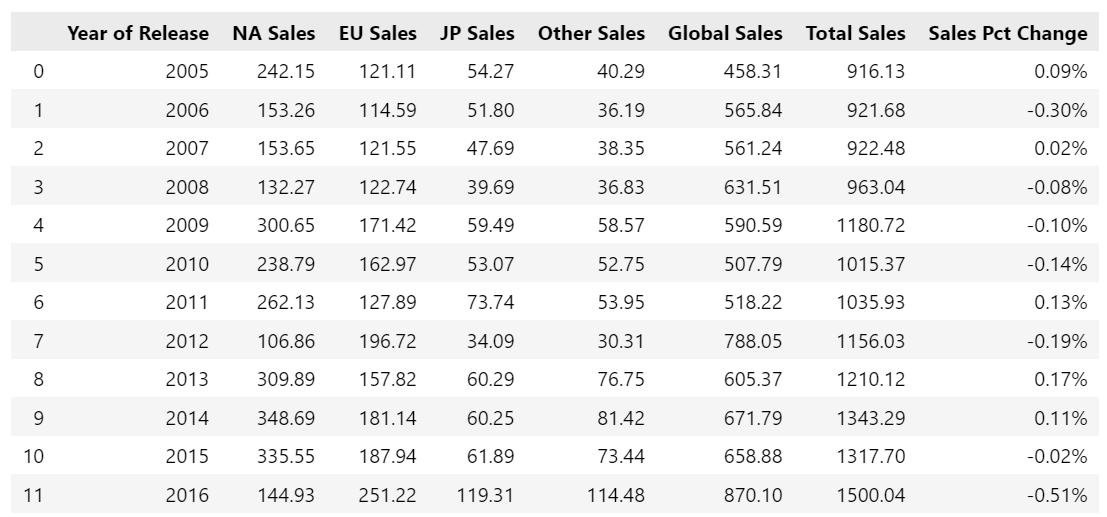
4) 질의/응답 리스트 작성

5) 답변 테스트
1️⃣ 기본 그래프 생성
df.ask('일본의 판매량에 대한 막대 그래프를 그려줘')
2️⃣ 비교 그래프 생성
'verbose=True'를 입력하면, 답변 생성에 활용된 파이썬 코드가 결과물에 나오게 됩니다.
df.ask('미국과 일본의 연도별 판매량에 대해 선 그래프를 그려줘', verbose=True)```python
import matplotlib.pyplot as plt
def process(df):
plt.figure(figsize=(10, 6))
plt.plot(df['Year of Release'], df['NA Sales'], label='NA Sales')
plt.plot(df['Year of Release'], df['JP Sales'], label='JP Sales')
plt.xlabel('Year')
plt.ylabel('Sales')
plt.title('Sales Data Over the Years')
plt.legend()
plt.show()
```
3️⃣ 데이터 설명
df.ask('EU 판매량 데이터에서 어느 년도가 가장 적게 판매됐어?', verbose=True)```python
import pandas as pd
def process(df):
min_eu_sales = df['EU Sales'].idxmin()
year_min_eu_sales = df.loc[min_eu_sales, 'Year of Release']
return year_min_eu_sales
```
4️⃣ 그래프 생성 + 간단한 데이터 설명
df.ask('2016년 미국의 판매량을 2015년과 비교해서 막대그래프를 그려주고, 몇 % 증감했는지 설명해줘')
5️⃣ 그래프 생성 + 복잡한 데이터 설명
df1 = df.drop(columns='Sales Pct Change')
df1.ask('2012~2014년도 미국의 연도별 판매량에 대해 막대 그래프를 그려주고, 년도별 증가/감소에 대해 설명해줘', verbose=True)그래프 및 데이터 설명 생성을 위해 사용된 코드입니다.
```python
import pandas as pd
import matplotlib.pyplot as plt
def process(df):
df_us = df[['Year of Release', 'NA Sales']]
df_us = df_us[(df_us['Year of Release'] >= 2012) & (df_us['Year of Release'] <= 2014)]
plt.figure(figsize=(10, 6))
plt.bar(df_us['Year of Release'], df_us['NA Sales'], color='skyblue')
plt.xlabel('Year')
plt.ylabel('NA Sales')
plt.title('NA Sales from 2012 to 2014')
plt.xticks(df_us['Year of Release'])
plt.grid(axis='y', linestyle='--')
diff_12_13 = df_us[df_us['Year of Release'] == 2013]['NA Sales'].values[0] - df_us[df_us['Year of Release'] == 2012]['NA Sales'].values[0]
diff_13_14 = df_us[df_us['Year of Release'] == 2014]['NA Sales'].values[0] - df_us[df_us['Year of Release'] == 2013]['NA Sales'].values[0]
if diff_12_13 > 0:
trend_12_13 = 'increase'
elif diff_12_13 == 0:
trend_12_13 = 'no change'
else:
trend_12_13 = 'decrease'
if diff_13_14 > 0:
trend_13_14 = 'increase'
elif diff_13_14 == 0:
trend_13_14 = 'no change'
else:
trend_13_14 = 'decrease'
print(f"From 2012 to 2013, NA sales {trend_12_13} by {abs(diff_12_13)} units.")
print(f"From 2013 to 2014, NA sales {trend_13_14} by {abs(diff_13_14)} units.")
plt.show()
```From 2012 to 2013, NA sales increase by 203.02999999999997 units.
From 2013 to 2014, NA sales increase by 38.80000000000001 units.
6️⃣ 복잡한 데이터 설명
df1.ask('2012~2014년도에 대해 미국의 년도별 증감 비율에 대해 설명해줘')
예제로 실습한 결과를 요약하면 다음과 같습니다.
- 답변 결과 👍
- 컬럼명을 정확하게 이해하는 편입니다.
(e.g. 컬럼명이 JP/NA와 같은 국가코드일 때, 질의에서 일본/미국'으로 질문해도 제대로 답변힙니다.) - 데이터에 대한 설명과 차트를 동시에 질문 시, 차트와 설명이 동시에 나옵니다.(그래프에 포함될 경우도 있음)
- 데이터 증감에 대해 정확히 답변합니다.
- 컬럼명을 정확하게 이해하는 편입니다.
- 답변 결과 👎
- 텍스트 답을 요구할 시, 문장으로 답변할 때가 있고, 숫자만 포함할 때가 있습니다. (예제3)
- 잘못된 코드가 생성되어, 에러가 발생하기도 합니다.
- 다수 건의 비율 계산을 요구할 시, 비율 계산은 잘하나 제한 조건이 제대로 걸리지 않습니다. (예제6)
5. Generative BI 파이썬 패키지 - pandas-ai
pandas-ai는 pandas에 생성형AI 기능을 추가한 python라이브러리입니다.
- 기능: 자연어 질의/응답, 그래프 그리기, 데이터 정제, 결측치 처리, 피처 생성
- 데이터 소스 연결 커넥터 제공 : PostgreSQL, MySQL Generic SQL. Snowflake, DataBricks, Yahoo Finance
- 다양한 LLM 적용 가능 : Open ai models, Google PaLM, Google Vertexai, Azure OpenAl, HuggingFace via Text Generation
- Langchain모델에 대한 지원 기능도 내장됨 (pip install pandasaillangchain)
- 에이전트를 사용하면 대화 내역 기억 및 에이전트가 응답에 어떻게 도달했는지 자세한 설명을 얻을 수 있음
- 'skillr'이라는 함수를 이용해, 사용자가 정의한 함수를 통합할 수 있음
- 커스텀 프롬프트 구성 가능
- 차트 이미지 자동 저장
다음은 간단한 예제로 실습한 내용입니다.
1) 파이썬 패키지 설치
%pip install -q pandasai
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from IPython.display import clear_output, display
clear_output()
2) Open AI-api key 설정
api_key = '<your api key>'
llm = OpenAI(api_token=api_key)
3) 데이터 로드
import pandas as pd
df = pd.read_csv('https://gist.githubusercontent.com/pleabargain/e79e39f56d04278d4e7bc64825de5196/raw/7e64971a126093298cd63644aeaec9d3d78d09b2/sample-sales-data.csv')
df = SmartDataframe(df, config={"llm": llm})
4) 질의/응답 리스트 작성
pandas-gpt의 예제와 같은 질의를 하였습니다.
5) 답변 테스트
1️⃣ 기본 그래프 생성
df.chat('일본의 판매량에 대한 막대 그래프를 그려줘')
2️⃣ 비교 그래프 생성
'verbose=True'를 입력하면, 답변 생성에 활용된 파이썬 코드가 결과물에 나오게 됩니다.
df.chat('미국과 일본의 연도별 판매량에 대해 선 그래프를 그려줘')
3️⃣ 데이터 설명
df.chat('EU 판매량 데이터에서 어느 년도가 가장 적게 판매됐어?')
4️⃣ 그래프 생성 + 간단한 데이터 설명
df.chat('2016년 미국의 판매량을 2015년과 비교해서 막대그래프를 그려주고, 몇 % 증감했는지 설명해줘')
5️⃣ 그래프 생성 + 복잡한 데이터 설명
df.chat('2012~2014년도 미국의 연도별 판매량에 대해 막대 그래프를 그려주고, 년도별 증가/감소에 대해 설명해줘')

6️⃣ 복잡한 데이터 설명
df.chat('2012~2014년도에 대해 미국의 년도별 증감 비율에 대해 설명해줘')
예제로 실습한 결과를 요약하면 다음과 같습니다.
- 답변 결과 👍
- 컬럼명을 정확하게 이해하는 편입니다.
(e.g. 컬럼명이 JP/NA와 같은 국가코드일 때, 질의에서 일본/미국'으로 질문해도 제대로 답변힙니다.) - 데이터에 대한 설명과 차트를 동시에 질문 시, 차트와 설명이 따로 나옵니다.
- 간단한 데이터에 대한 증감을 질의할 시 정확히 답변합니다.
- 컬럼명을 정확하게 이해하는 편입니다.
- 답변 결과 👎
- 차트와 차트에 대한 복잡한 설명(e.g. 다수 건의 비율 산출)을 요구할 시, 차트만 그려주는 경우가 발생합니다.
(→ 복잡한 설명이 필요할 시에는 차트와 데이터 설명을 분리해서 질의할 필요가 있습니다.)
- 차트와 차트에 대한 복잡한 설명(e.g. 다수 건의 비율 산출)을 요구할 시, 차트만 그려주는 경우가 발생합니다.
추가적으로, 'skill'을 이용하여 Agent 기능을 적용한 예제입니다.
import pandas as pd
from pandasai import Agent
from pandasai.llm.openai import OpenAI
from pandasai.skills import skill
# Function doc string to give more context to the model for use this skill
@skill
def plot_sales(year: list[int], sales: list[int]):
"""
Displays the bar chart having name on x-axis and sales on y-axis
Args:
year (list[int]): year
sales (list[int]): sales
"""
# plot bars
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,4)) ## Figure 생성
fig.set_facecolor('white') ## Figure 배경색 지정
xtick_label_position = list(range(len(year))) ## x축 눈금 라벨이 표시될 x좌표
plt.xticks(xtick_label_position, year) ## x축 눈금 라벨 출력
plt.bar(xtick_label_position, sales)
plt.plot(xtick_label_position, sales, color='b',
linestyle='--', marker='o') ## 선 그래프 출력
plt.title('Total sales for year', fontsize=20)
plt.show()
llm = OpenAI(api_token=api_key)
agent = Agent([df['Year of Release'], df['Total Sales']], config={"llm": llm}, memory_size=10)
agent.add_skills(plot_sales)
# Chat with the agent
response = agent.chat("년도별 전체 판매량(total sales)에 대해 바그래프와 선그래프를 그려줘")
response| 'skill' 적용 전 | 'skill' 적용 후 |
 |  |
6. Results
toy data로 간단한 테스트를 진행한 결과, pandas-gpt와 pandas-ai의 사용 문법은 굉장히 비슷하였습니다.
(pandas-gpt => pd.DataFrame.ask(''), pandas-ai=> pd.DataFrame.chat('') 로 질의에 대한 답변을 받을 수 있습니다. )
그리고 두 패키지 모두 데이터에 기반하여 간단한 차트와 데이터에 대한 설명을 잘 수행하는 것으로 나타났습니다.
그러나 차트와 동시에 복잡한 설명을 요구할 경우에는 두 패키지 모두 답변이 미흡한 경향이 있습니다.
또한 두 패키지를 비교하면, pandas-ai에 내장된 기능들이 다양하여 pandas-gpt보다는 활용도가 더 높을 것이라 판단됩니다.
📚 [참고문헌]
https://docs.aws.amazon.com/ko_kr/quicksight/latest/user/quicksight-q-get-started.html
아마존 QuickSight Q 시작하기 - 아마존 QuickSight
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
https://docs.pandas-ai.com/en/latest/getting-started/
Getting Started - PandasAI
Before installation, we recommend you create a virtual environment using your preferred choice of environment manager e.g Poetry, Pipenv, Conda, Virtualenv, Venv etc. In order to keep the installation size small, pandasai does not include all the dependenc
docs.pandas-ai.com
https://pypi.org/project/pandas-gpt/
pandas-gpt
Power up your data science workflow with ChatGPT
pypi.org
'Data Science&AI' 카테고리의 다른 글
| [Model Drift] Model Drift에 대한 A to Z # 2. Detection 방법과 Handling 방법 (0) | 2023.05.29 |
|---|---|
| [Model Drift] Model Drift에 대한 A to Z # 1. 정의와 유형 (0) | 2023.05.29 |
| [시계열 알고리즘] NHiTS : Neural Hierarchical Interpolation for Time Series Forecasting (0) | 2023.04.04 |
| [딥러닝] BERT와 GPT의 기본인 Transformer의 A to Z (1) | 2023.02.26 |
| [딥러닝] Attention에 대한 설명 (0) | 2023.02.18 |
- Total
- Today
- Yesterday
- pandas-ai
- 비즈니스 관점 AI
- 추천시스템
- AutoEncoder
- 최신시계열
- 모델 드리프트 대응법
- Data Drift Detection
- 영어공부
- SQLD 정리
- Model Drift
- Tableau vs QuickSight
- SQLD자격증
- Data Drift와 Concept Drift 차이
- Concept Drift
- NHITS설명
- Model Drift Detection
- 오토인코더
- pandas-gpt
- 생성형BI
- 시계열딥러닝
- 모델 드리프트
- 데이터 드리프트
- 영화 인턴
- amzaon quicksight
- Generative BI
- SQLD
- data drift
- On-premise BI vs Cloud BI
- 모델 배포
- amazon Q
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |